Medical and Technical Background#
Carpal Tunnel Syndrome#
Carpal tunnel syndrome (CTS) is the most common condition of peripheral nerve entrapment worldwide [3] . It is an entrapment nephropathy, a damage to the nerve in the regions where it passes through narrow spaces. Even if just a small region of the nerve is damaged, neuropathies can have a significant impact physically, psychologically, and economically, since they can lead to a loss of function of the affected areas and a disability to fulfill simple daily tasks [3] .
The carpal tunnel condition occurs when the median nerve, one of the major nerves to the hand, is squeezed or compressed as it travels through the wrist. The symptoms are pain, numbness, and tingling in the hand and arm, and they can be classified into mild, moderate, or severe cases [4]. The elderly population is the most affected by the condition, and it is most prevalent in women compared to men [5] . It is highly correlated to work activities that cause strain and repetitive movements, as well as extended positions in excesses of wrist flexion or extension, monotonous use of the flexor muscles, and exposure to vibration:footcite:Geoghegan.2004 . Compression may occur from space-occupying lesions on the wrist or mechanical stress of the nerve caused by contact with the surrounding tendons. The incidence rate might also increase for some specific categories such as cyclists, wheelchair users, wrestlers, or extensive computer users [6]. CTS may moreover be associated with hypothyroidism, diabetes menopause, obesity, arthritis, and pregnancy, which makes suspect relations not only to mechanical damage but also to hormonal changes [3] .
The pathophysiology of CTS comprises a combination of mechanical trauma, elevated pressure in the carpal tunnel, and ischemic damage to the median nerve. In most patients, it worsens over time, so early diagnosis and treatment are important. The first symptoms of the illness are sporadic, nighttime paraesthesias and dysaesthesias that become more frequent and happen during the day. Later in the course of the disease, loss of feeling, weakness, and muscle atrophy follow, all of which are caused by severe axonal degeneration [7] . Early on, symptoms can often be relieved with simple measures like wearing a wrist splint or avoiding certain activities. However, more severe cases need surgical interventions, such as open release and endoscopic surgeries.
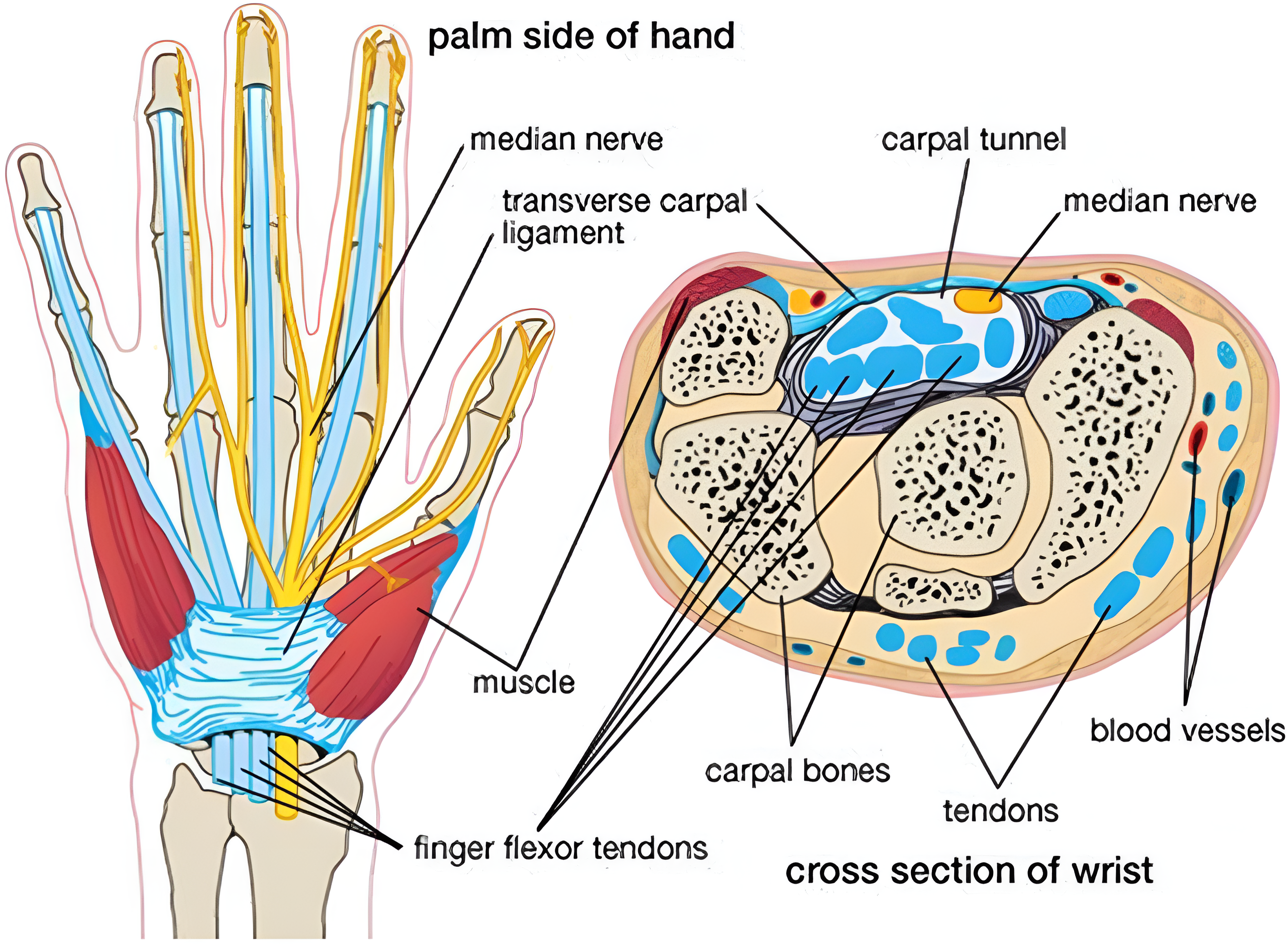
Fig. 1 Figurative structure of the carpal tunnel and of the median nerve branches. Figure from [8].#
Carpal Tunnel Anatomy#
The carpal tunnel is a narrow passageway located on the palm side of the wrist, and its anatomy can be visualized in Fig. 1. It is defined by the flexor retinaculum on the top, which forms a roof over the tunnel, and the carpal sulcus on the bottom. The carpal bones delimiting the tunnel at the ulnar edge are the hamate hook, the pyramidal bone, and the psiform bone, while the radial edge is formed by the scaphoid bone, the trapezoid bone, and the tendons of the flexor carpi radialis (FCR) muscles. The bones at the base are the underlying portions of the scaphoid, lunate, capitate, hamate, trapezium, and trapezoid.
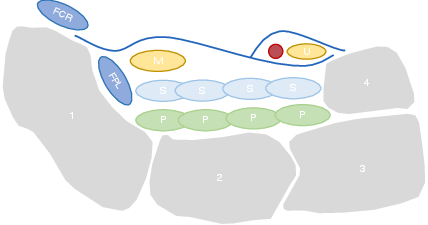
Fig. 2 Simplified transversal structure of the carpal tunnel. 1 - Scaphoid bone; 2- Lunate bone; 3 - Triquetrum bone; 4 - Psiform bone; FCR - flexor carpi radialis; FPL - Flexor pollicis longus; S - Flexor superficialis tendons; P - Flexor profundus tendons; M - Median nerve; U - Ulnar nerve. Figure adapted from [6] .#
The median nerve, which controls sensation and movement in the thumb and first three fingers, runs through this passageway along with the superficial tendons of the fingers and the long flexor of the thumb. After the tunnel, the nerve divides into six different branches. Nonetheless, the anatomy of the nerve may present some variations, which explain the different symptoms and make the diagnosis more difficult [5] .
CTS Diagnosis#
The diagnosis of CTS is usually based on the history of the patient associated with the characteristics of the condition. The patients are usually asked to describe their symptoms and their frequency. In addition, the physician may inquire about the patient’s daily activities, work, and hobbies, as well as any medical conditions to asses any predisposing factors [9] .
Thereafter, the physician may perform a physical examination, which includes specific tests and maneuvers to assess the function of the median nerve and the control and strength of the hand motor functions [10] . If the patient’s medical history, symptoms, and physical examination lead to a CTS suspect, further examinations are conducted to confirm the diagnosis, determine the severity, and plan the treatment. A comparison between the different diagnostic techniques is summarized in [tab:diagnostic].
A standard diagnostic procedure for CTS is the electrodiagnostic testing, which consists in measuring the electrical conductivity of the nerve along its three main branches. It helps to assess quantitatively the severity of entrapment, but it is prone to false negatives and false positives, it is time-consuming and it does not give any insight into the anatomy of the carpal tunnel.
A better and more expressive evaluation of the CTS is to measure the cross-sectional area (CSA) of the nerve, which can be visualized with medical imaging techniques. Magnetic Resonance Imaging (MRI) offers good visualization of the complete anatomy but it is expensive and time-consuming. Moreover, the accurate segmentation of the median nerve depends on the operator’s experience.
Finally, sonographic imaging has become a popular method to assess carpal tunnel syndrome since it offers real-time visualization, and is portable and accessible [11][12] . It can reach resolutions of less than 1 mm, thanks to advancements in technology such as affordable high-frequency probes, enabling the diagnosis of the CT condition by visualization of the nerve’s structure [13] . Carpal tunnel syndrome is believed to cause morphological changes to the median nerve resulting from compression by the surrounding nonrigid tissues. This effect reduces nerve volume at the site of compression while increasing size proximal (and sometimes distal) to the compression [3] . However, the operator dependency and the lack of standardization in the acquisition protocol can lead to inconsistent results [14] . Moreover, the procedure is time-consuming and requires long operator training and high expertise. Due to the low contrast of nerve tissue in the image and its low variability from other tissues, the median nerve is very difficult to segment.
Electrodiagnostic Testing |
Magnetic Resonance Imaging |
Ultrasound Imaging |
|---|---|---|
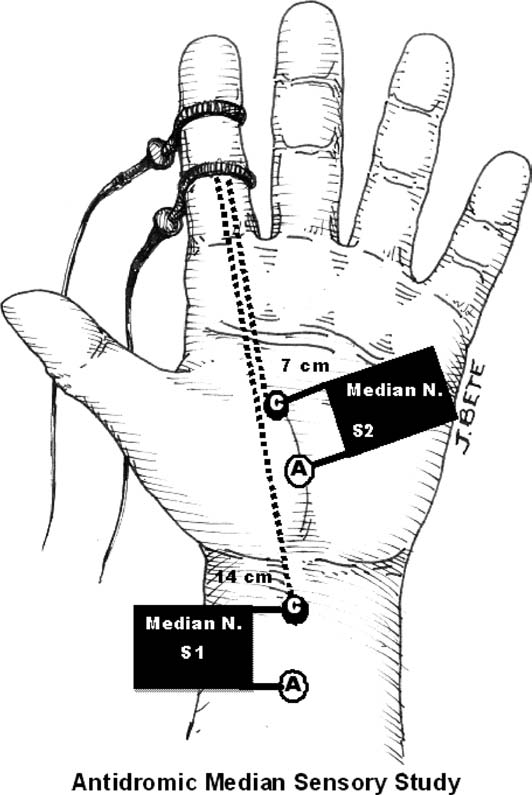
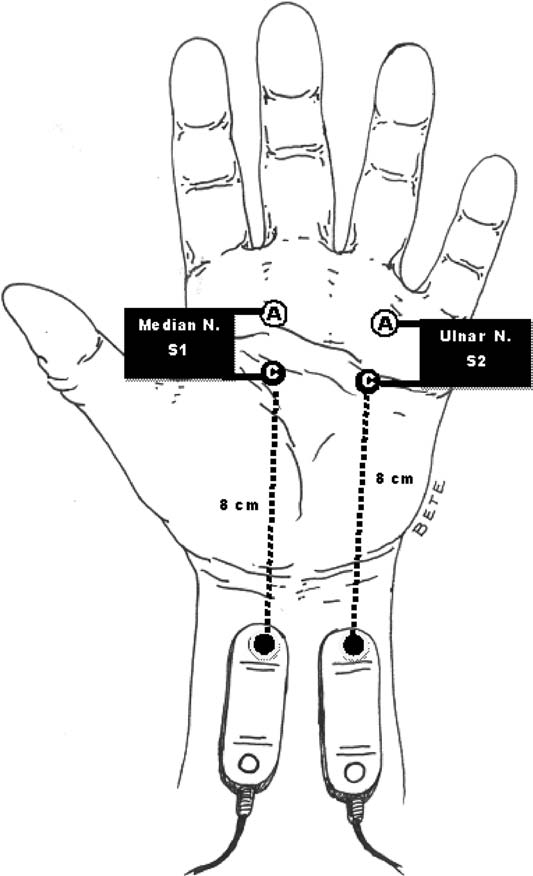
Antidromic stimulation in the palm with recording at the index finger or middle finger. |
Axial T1 evaluates the tendons of the wrist and carpal tunnel, including the flexor retinaculum. |
Positioning of the probe to analyze the median nerve at the level of the distal third of the forearm and of the carpal tunnel at the scaphoid-pisiform level. |
|
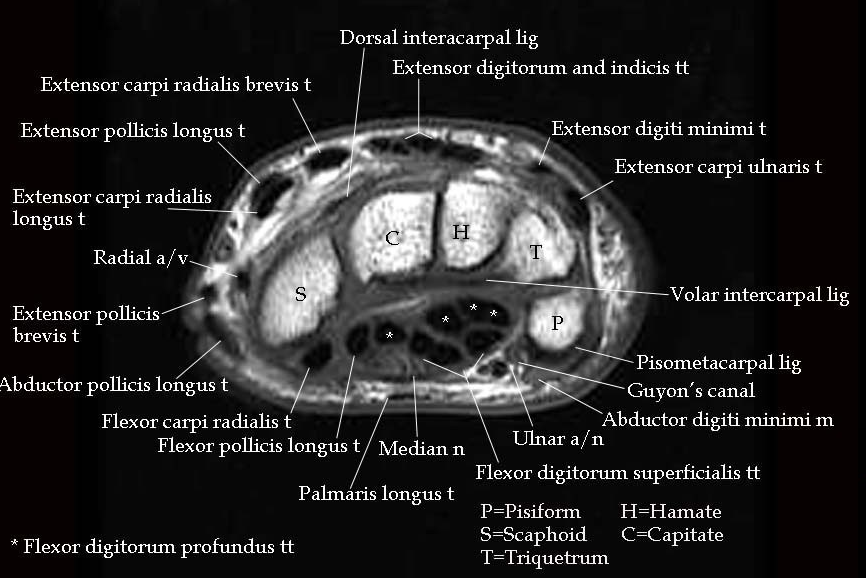
Fig. 3 MRI of the carpal tunnel at the Psiform-Scaphoid standard plane. Figure from [16].# |
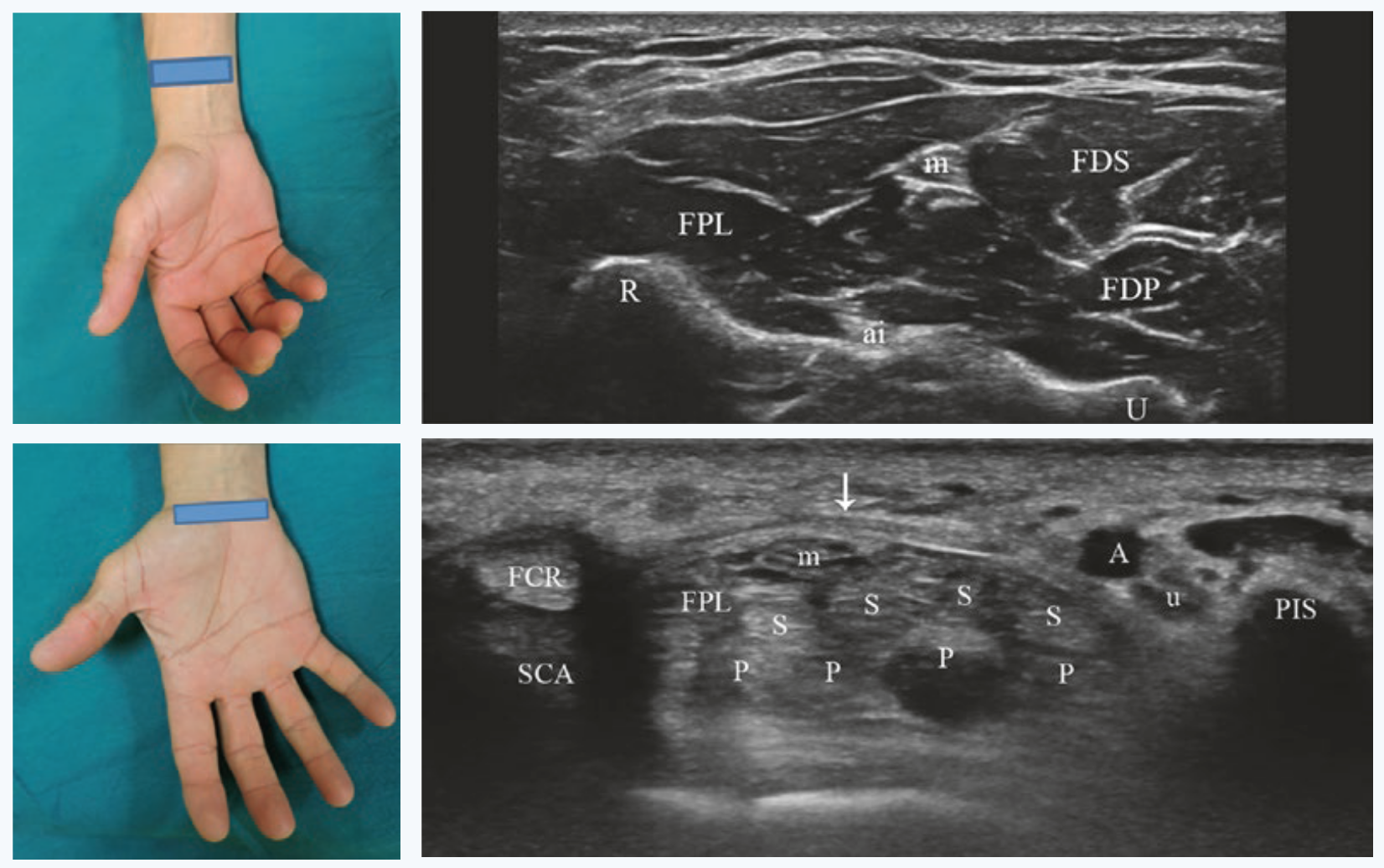
Fig. 4 Standard positions for median nerve visualization at the carpal tunnel and at distally at its free exit. Figures from [6].# |
Pros: |
||
|
|
|
Cons: |
||
|
|
|
Ultrasound Imaging#
Ultrasound imaging (US), also known as sonography, is one of the most widely used medical imaging techniques [17]. It is a non-invasive medical diagnostic technique that uses high-frequency sound waves to visualize in real time the internal human body structures including soft tissues, such as organs, musculoskeletal system, nerves, and blood flow.
Thanks to the real-time visualization, portability, absence of ionizing radiation, high sensitivity, and image resolution, US scanning applications are continuously increasing [18]. It is widely employed across various medical specialties, including obstetrics, cardiology, gastroenterology, and musculoskeletal imaging. One of the key advantages of ultrasound imaging is its safety making it particularly suitable for monitoring pregnant women and pediatric patients. The real-time nature of ultrasound allows for dynamic assessments, enabling healthcare professionals to observe moving structures and assess blood flow patterns. Additionally, ultrasound is instrumental in guiding minimally invasive procedures such as biopsies and injections.
Ultrasound Properties#
The basic principle underlying ultrasound imaging involves the emission of sound waves from a transducer, a device emitting and receiving these waves. Sound waves are characterized by frequency, wavelength, amplitude, period, velocity, power, and intensity [6]. These waves travel through the body, encountering tissues with varying acoustic properties. When the sound waves encounter a boundary between tissues of different densities, some waves are reflected to the transducer, while others continue to penetrate deeper. The returning waves are then converted into electrical signals, and sophisticated computer algorithms analyze these signals to create high-resolution images.
Nerves Ultrasound Imaging#
Peripheral nerves consist of nervous fibers composed of axons grouped into fascicles:footcite:Stewart.2003. Each fascicle is covered by the perineurium, a connective tissue layer, and the whole nerve is surrounded by the epineurium, the outermost dense sheet of connective tissue. The axons forming the fascicles are surrounded by the endoneurial fluid, which is a mixture of water, proteins, and electrolytes. The connective tissue that envelops the axon is the endoneurium. Moreover, each axon is wrapped into the myelin sheath, a lipid-rich layer produced by the Schwahn cells that insulate the axon and is responsible for the rapid conduction of nerve impulses.
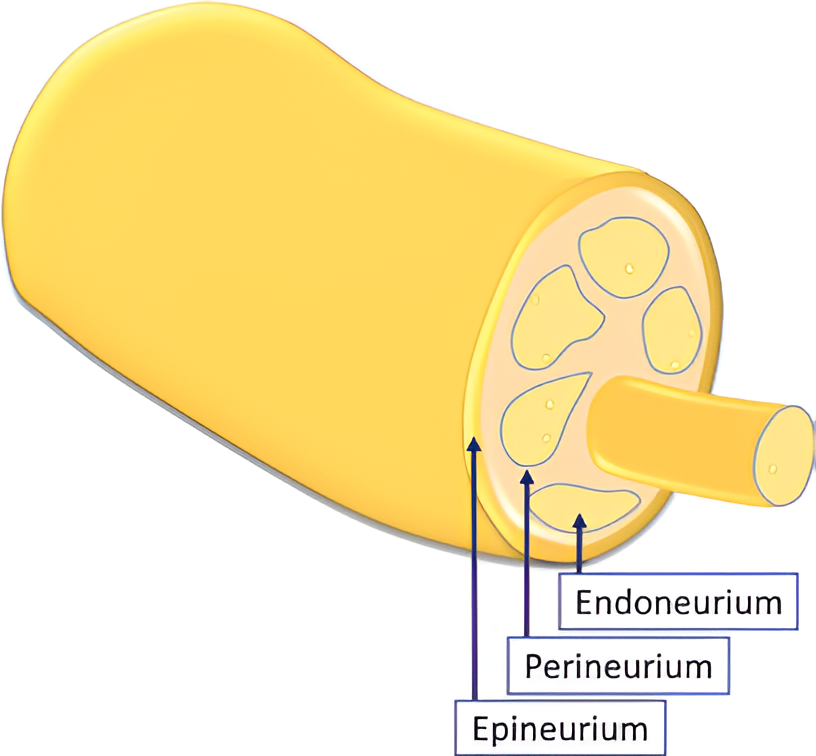
Fig. 5 Scheme depicting the inner structure of the peripheral nerve [6].#
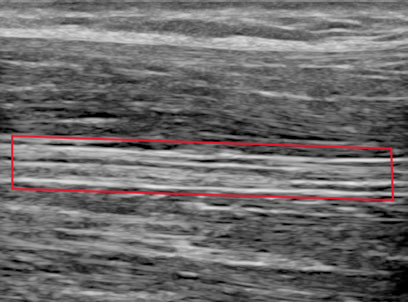
Fig. 6 Longitudinal view of the median nerve (red box) with ultrasound [6].#
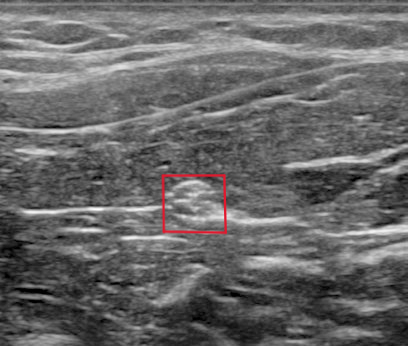
Fig. 7 Transverse view of the median nerve (red box) with ultrasound [6].#
Because of their anatomical structure, nerves present a cable-like structure recognizable in the ultrasound image, as in Fig. 5. In the longitudinal plane, nerves appear as long and thin structures, with parallel lines representing the perineurium of the axons and two noticeably thicker lines of the epineurium, as is visible in Fig. 6. In the transverse plane, nerves resemble a honeycomb of round areas, composed of the fascicles surrounded by the perineurium thicker layer, visible in Fig. 7. This is the most common view in clinical practice since it permits locating the nerve at standard positions between specific anatomical landmarks, and tracking it distally or proximally [6]. Moreover, transversal imaging displays the nerve’s shape and allows to asses its size, vasculature, and relation to the surrounding tissues.
Nerves are recognizable in US images due to their characteristic isotropy [6]. Anisotropy means that the angle of incidence equals the angle of reflection, which makes tissues look brighter with perpendicular insonation. This is a typical characteristic of tendons. Nerves, on the other hand, are isotropic, meaning that they have a uniform behavior regardless of the angle of incidence. This is because the nerve is composed of a mixture of tissues with different acoustic properties, making the reflection of the sound waves more complex.
Nerve shapes vary across individuals, including round, oval, triangular, and irregular shapes. Moreover, these can alter during a scan because of probe pressure or muscle activity. Nerves can even change form along their course and may have anatomical variations, such as the bifid or trifid versions of the median nerve.
Nerve Localization#
As mentioned before, to detect a nerve it is crucial to have knowledge of the anatomical topography of the surrounding structures of the nerve in a particular region. This is because the nerve is not always visible in the image, and it is often necessary to identify it by its relation to other structures.
For median nerve localization, different landmarks are used at different regions of the arm: the brachial artery for the upper part of the arm, the superficial and deep flexor muscles for the forearm, and the carpal tunnel anatomy at the wrist [6].
Robotic Ultrasound Scanning#
Despite its popularity, medical US imaging has some important drawbacks. US examination relies on the skills and experience of the sonographer, who must be able to identify the correct field of view. This consists of the manual task of holding the probe with appropriate pressure and the technical task of tuning the machine to set the right ultrasound parameter to have the best visualization outcome. It presumes a good knowledge of the physical foundation of the technique as well as the technical properties of the equipment [6] . As a result, the quality and repeatability of a US scan are highly operator-dependent, which makes reproducible image acquisition very difficult.
Guiding a probe to visualize target objects in desired planes in medical ultrasound images is an extremely complex task. This complexity arises from potential tissue deformation and inconsistent acoustic artifacts present in these images. Consequently, it necessitates several years of specialized training [19].
Moreover, the excessive workload exposes sonographers to health issues such as musculoskeletal disorders and regional pain, because of the constant pressure that they need to apply throughout a scan several times a day [20][21].
Robotic ultrasound scanning (RUSS) is a promising solution to these issues. It is the fusion of a robotic and an ultrasound system with its probe attached to the robot’s end-effector. It aims to automate the scanning process, reducing operator dependency and increasing the repeatability of the examination. The level of robot autonomy can be divided into three main groups: teleoperated, collaborative assistance, autonomous systems [22].
RUSS Levels of Autonomy#
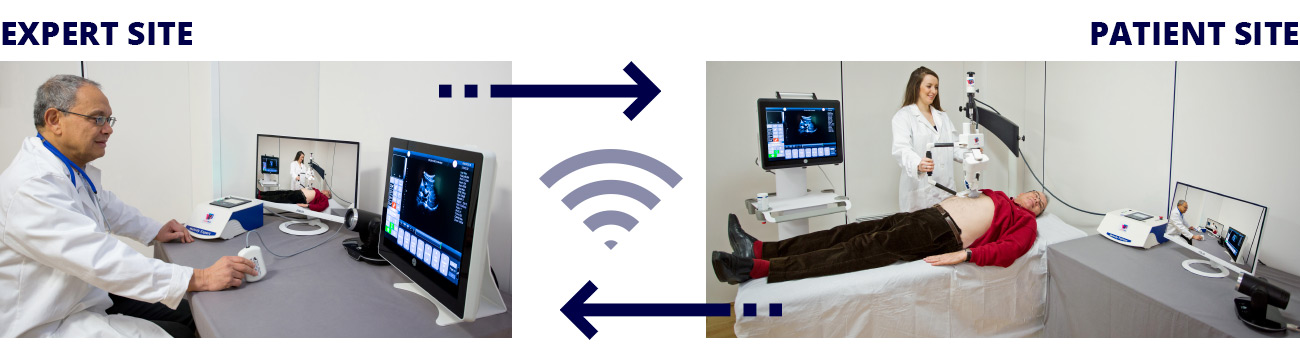
Remote control of the ultrasound probe by teleoperation is the first step to implementing robotic assistance in US scanning. The operator can control the robotic arm from a distance, be assisted by applying pressure during the scan, or even just profit from the position tracking of the robotic system. Commercial systems for teleoperated ultrasound are available, such as the MGIUS-R3 (MGI Tech Co.) system [23] or the MELODY (AdEchoTech) system [24] . These systems consist of a robotic arm with a force feedback sensor that holds the probe and can be controlled by the operator through a dummy probe up to six degrees of freedom (DOF).

Collaborative assistance is the next step towards robot autonomy. The goal is usually to assist clinicians conduct the procedures quickly, precisely, and consistently. In their work, Jiang et al. [25] improve image quality by optimizing the orientation of the RUSS probe, aligning it to the normal of the scanned tissue’s surface at the contact point. Another example is the work from Virga et al. [26], which implements an assistive control to limit the contact pressure applied on the contact surface, to estimate and correct the induced deformation. Collaborative robots can also offer therapy guidance in tasks such as needle insertion. Assistance might provide respiratory motion compensation [27] , or assist venipuncture by reconstructing and tracking a superficial vessel as shown in Chen et al. [28] using infrared sensors and automatic image segmentation. Efforts have been made to replace external force sensors with integrated torque sensors in lightweight robots, enhance motion compensation, speed real-time imaging, and improve calibration [29] .
Autonomous systems are those capable of independent task planning, control of the robot, and real-time task optimization, responding to simultaneous possible system changes. The robot must be able to adapt to the patient’s anatomy, to the probe-tissue interaction, and to the image quality. The more autonomy the robot has, the less the operator is involved in the scanning process and can therefore concentrate on interventions or diagnostic tasks. Most of the proposed solutions offer assistance for 3D image reconstruction, trajectory planning, probe positioning, or image quality optimization [29] .
The technical key developments that enable autonomous or semi-autonomous scanning from a robotic perspective is the control of three fundamental parameters: contact force, probe orientation, and scan path planning [30]. These are adjusted by the robot control system under the constraints to ensure the patient’s safety. The information necessary for path planning coming from the currently observed images and the current position must be interpreted automatically to determine the next steps.
To develop a control based on visual servoing, online access to the real-time images is necessary. This might be done by grabbing directly the frames displayed by the ultrasound system in case of 2D images. However, in the case of a 3D US scanner, the data is more complex and a streaming interface must be implemented. In addition, remote or automatic control of the imaging tuning parameters also needs to be externally developed.
Autonomous RUSS are highly application specific and have had a greater development with the rise of AI applications. In particular reliable navigation was recognized to be a missing step of research by von Haxthausen et al [29] . Different approaches to automatic path planning and navigation will be presented in RUSS Navigation Systems, drawing the motivation for a new navigation system based on the current observations, which emulates the way human sonographers perform ultrasound scans.
RUSS Navigation Systems#
The integration of artificial intelligent systems in US imaging, particularly deep learning and convolutional neural networks (CNNs), has achieved great results in image processing tasks, offering great support in segmentation and classification of anatomical regions, including that of the carpal tunnel [31][32][33][34] . However, to segment meaningful structures, the specific region of interest (ROI) should be visible in the image. This means that the search problem is only partially solved if not integrated with an autonomous image acquisition, since the system will expect to receive an optimal image.
Locating standard examination planes for biometric measurements and diagnoses is often a challenging and time-consuming task for sonographers. To achieve a fully autonomous system, it is necessary to develop a system that can navigate to the standard US planes at which determined structures can be recognized. Path planning and consequent navigation control is a fundamental capability for the advancement of autonomous robotic systems. Thanks to the fast development of artificial intelligence (AI), learning-based methods are improving the autonomy of RUSS [30] .
Autonomous Navigation with Reinforcement Learning#
Autonomous path planning and navigation has been mainly addressed by depth camera-based approaches, US image segmentation-based servoing, human interaction or pre-operative image-based planning. However, these methods are limited by the need for a pre-defined path, the necessity of a human operator to initiate the task, the tracking of simple anatomies, or the requirement of a pre-operative image.
The advancement of Reinforcement Learning (RL) algorithms and their application in this research field can significantly enhance the autonomy of robotic ultrasound scanning and address the image-based optimization problem. Additionally, AI techniques have the potential to deepen the understanding of ultrasound procedures by incorporating the expertise of experienced sonographers’ anatomical knowledge.
RL is a goal oriented approach, and it is particularly suited to solve search problems in high dimensional state spaces, such as searching specific anatomical features or navigate to a standard US view. It allows the agent to learn a policy that maps the current state of the system to an action that maximizes a reward signal.
Milletari et al. [36] created a grid simulation environment using recorded scans over the patients’ chest to train a deep Q-Network (DQN) agent [37] for cardiac examination assistance. At inference time, the user functions as the agent, receiving motion recommendations from the RL policy to manually complete the navigation loop. The research demonstrated better results than supervised methods.
Hase et al. [38] employed a similar approach, training an agent to locate the standard view of the sacrum in a US scan of the patient’s back. The code of this project is publicly available [1]. The authors recorded an in-house dataset of lower back US scans of 34 volunteers, using precise position tracking via a robotic sweep. The interaction environment was simulated by creating a grid space over the recorded scans, with the agent’s action space consisting of movements along two dimensions of the grid: up-down, and right-left. The state is fully defined by the probe’s position, which is not directly observable. Thus, the task is modeled as a Partially Observable Markov Decision Process, requiring the agent to infer its state from the current observation. The observations include the current US frame at the probe’s position, stacked with the previous three US frames and actions. The training reward is based on the Euclidean distance from the current state to the goal position, which must be labeled in the training dataset. The agent is rewarded for the amount of pose improvement. The navigation terminates when a binary classifier identifies the current image as the sacrum standard plane. A correct stop leads to a high positive reward and an incorrect stop to a high negative reward. Since the agent is only able to move in 2-DOF (vertical and horizontal translation), careful initialization of the probe orientation is essential.
The authors show the results for three variations of the algorithm. The first one, called V-DQN, does not include the action memory, but only a stack of previously observed frames, and it does not use the binary classifier to decide when to stop the navigation. In the M-DQN version, the action memory is included. Then they test both pipelines including the binary classifier as a termination criteria in the VS-DQN and MS-DQN versions. Fig. 9 shows a diagram of the network architecture. The results demonstrate that the inclusion of the action memory and the binary classifier improves the navigation performance, with the MS-DQN being the best-performing model.
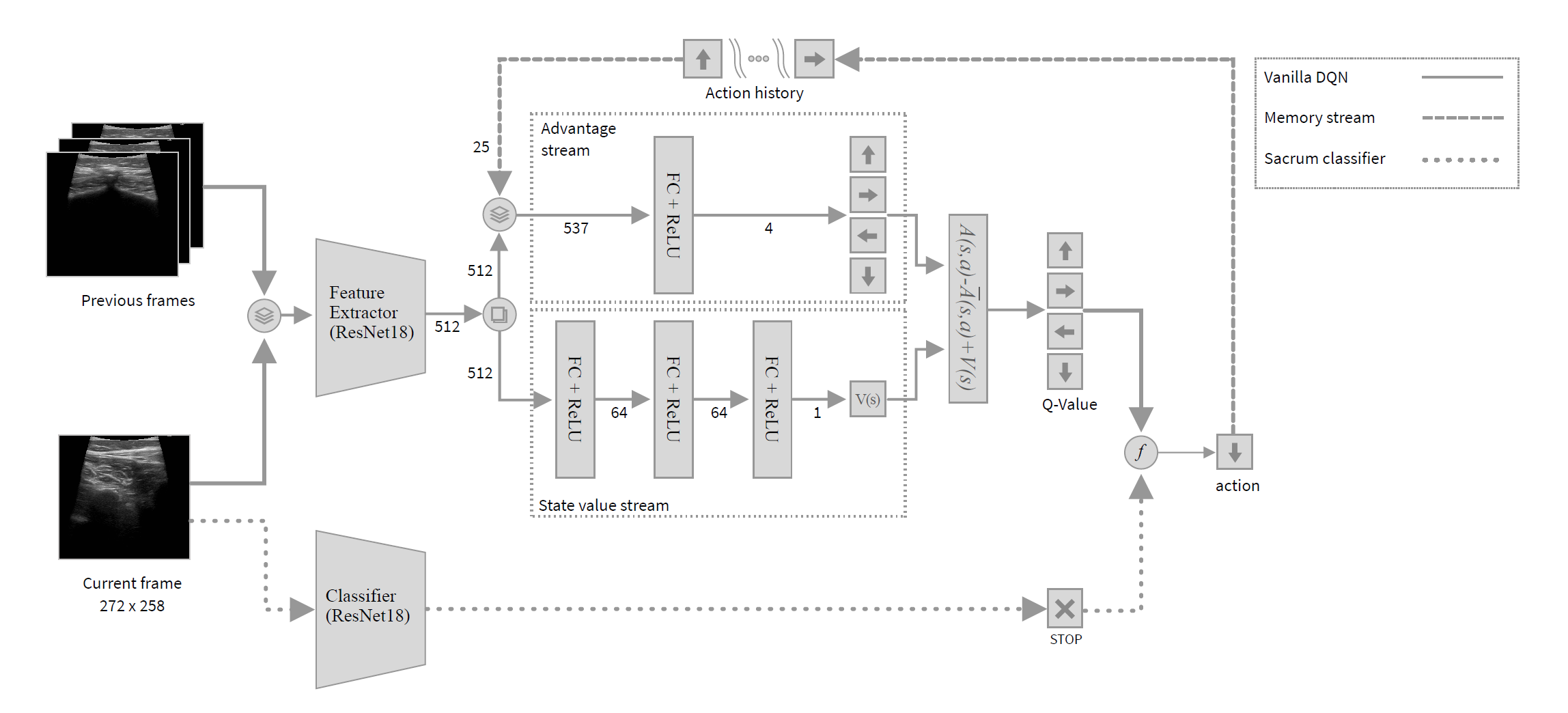
Fig. 9 Network architecture of the DQN agent for the sacrum standard plane navigation task. The solid line represents the V-DQN, the broken line connects the action history included in the M-DQN, and the dotted line represents the binary classifier included in the VS-DQN and MS-DQN.Figure from [38].#
As it can be understood from the network architecture, the policy learns to take actions based on the output of a neural network which receives the stack of observed US image frames as input. Features are extracted by a ResNet18 [39] , which are then used to estimate the state values and the advantage functions. State value expresses the expected return from a given state onwards, while the advantage function is an estimate of how much better it is to take a specific action in a given state compared to the average action. Advantage estimation and state value function together define the Q-value, which is the final estimate of the best action to take.
Li et al. [40] developed a similar simulator using a 3D US volume, expanding the action space to 5-DoF: 3 rotational axes and 2 translations, with vertical translation fixed to constant skin contact. This method allows for arbitrary probe navigation, defined by consecutive transformations. Each translation and rotation change is however bound to a discrete step size. The step size is reduced by one unit when the pairwise distance between three historical poses is smaller than a threshold until it reaches zero. The state space is therefore larger, and it is defined by a transformation matrix \(T_{W}^{P}\) from a world coordinate frame \(W\) to the probe position \(P\). The problem remains a POMDP, so the state is not fully observable.
The observation space is defined by the stack of last observed frames, to account for dynamic informations. The reward function, similar to Hase et al. [38] , is proportional to the amount of pose improvement: \(\delta d_t\) calculates the location improvement and \(\delta \omega_t\) the orientation improvement. The episodes are terminated if the agent exceeds the maximal number of steps, if it moves out of the simulation volume, or if it converges to a pose until the action-step is reduced to zero. Wrong termination is penalized, while reaching the goal is highly rewarded. Moreover, a confidence-based method is included in the reward estimation, \(\delta c_t\), which introduces the optimization of image quality in the navigation strategy.
Paper |
Hase et al. [38] |
Li et al. [40] |
Bi et al. [41] |
|---|---|---|---|
Situation |
Reward |
||
Move closer |
0.05 |
\(\Delta d_t + \Delta \omega_t\) |
\(\nu_t - \nu_{t-1}\) |
Move away |
-0.1 |
||
Correct termination |
1.0 |
10 |
5 |
Wrong termination |
-0.25 |
||
Out of bounds |
-1 |
-0.2 |
The authors implement the DQN algorithm with minor modifications. The Q-network is pre-trained on some optimal trajectories generated with an expert policy that maximizes the one-step pose improvement. It adopts a SonoNet-16 architecture [42] to extract features from the US images.
The observation spaces of the environments that have just been presented are both based on the observed US images. The value functions that lead the policy to decide which action to take are based on the features extracted by the convolutional neural networks from these images. It is however difficult to predict upon which kind of features the agent will base its choice of action, and whether these will overfit to the set of participants’ scans used for training.
In order to achieve better generalization and bridge the gap between simulation and the real-world, Bi et al. [41] developed VesNet-RL, an RL framework to perform US standard plane searching for vascular anatomies. The intuition is to simplify the observation to remove irrelevant information from the background. Instead of considering the full US image, they first segment the vessel with a UNet and then run RL on the segmentation result. This opens the possibility to use simulated binary images in the training loop, expanding the diversity of the training set. An advantage actor-critic agent is trained to navigate to the optimal longitudinal view of the carotid artery following the center line of the segmented vessel. A schematic overview of the system is represented in Fig. 10.
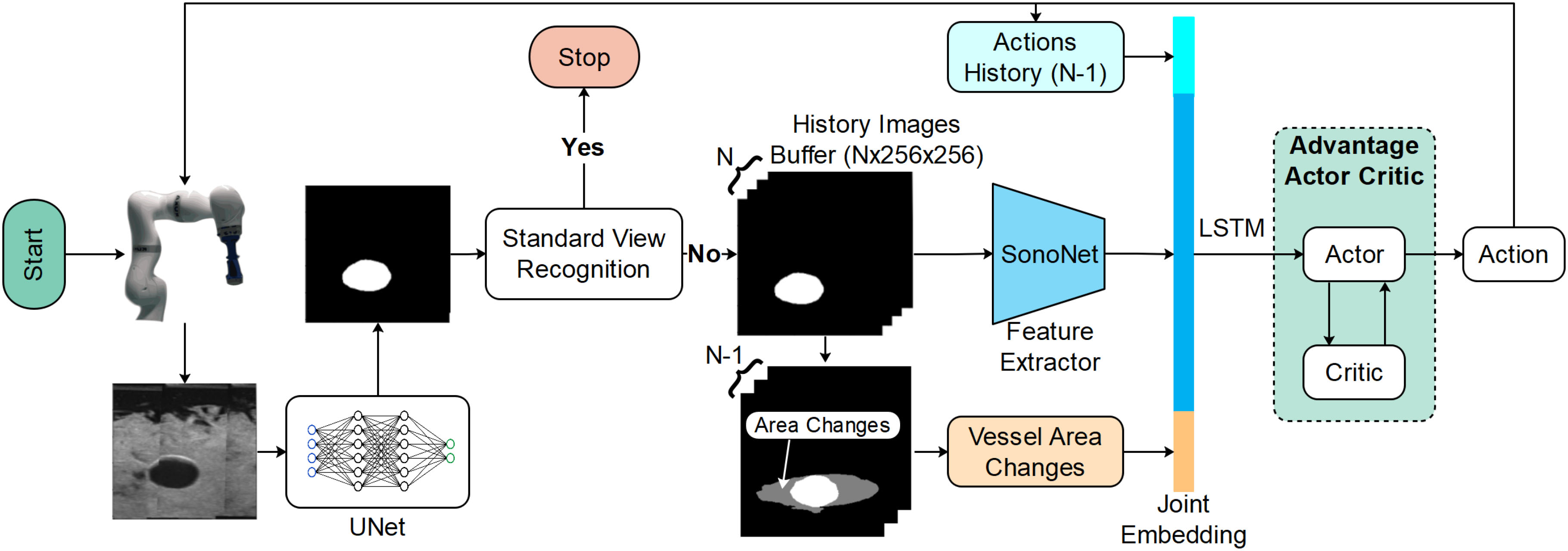
Fig. 10 VesNet-RL: The agent is trained to navigate to the optimal longitudinal view of the carotid artery following the center line of the segmented vessel. Figure from [41]#
The action space of the environment is defined in end-effector coordinates, with discrete translations along X- and Y-axes and discrete rotations around the Z-axis. The observations contain information about the last seen frames, latest actions, and vessel area changes. Before being fed to the RL agent, the images are processed for feature extraction by a slightly modified SonoNet-16 Network [42] . As done in previous approaches, a stack of last observed images is used to take account of the dynamic. The reward considers the amount of pose improvement \(\nu_t\), which increases when getting closer to the goal and for a larger vessel area. If the size of the segmented area is smaller than a threshold \(D_{th}\), or if no vessel is segmented, the navigation is considered out of bounds and is penalized. The termination is calculated based on the minimum bounding box of the vessel. A positive reward is given for getting close to the goal and a larger reward is given when the goal is reached.
Using a UNet to preprocess the observations improves generalization. The vascular segmented US images will have similar geometries also in different applications, permitting the implementation of the same approach to similar anatomies, by just retraining the UNet rather than the entire RL agent. Given that RL algorithms rely on experience-driven learning, it is clear that using low-dimensional representations is preferable to high-dimensional ones when both can encapsulate the required information. Moreover, it allows to easily simulate new environments’ information with binary values. However, such simulation methods can only be used for relatively simple anatomies.
Learning navigation on MRI and CT Labelmap Volumes#
The use of labelmaps volume to train the navigation system is a promising approach to simplify the observation space of the environment. Firstly, labelmaps provide a simplified and low-dimensional representation of observations. Similar to segmentation outputs, labelmaps eliminate background noise, highlighting only the critical features. This is comparable to how experienced sonographers navigate using anatomical landmarks, which can be replicated in the RL training process. The assumption is that transfer learning methods will effectively simulate ultrasound images from labelmaps, enabling accurate segmentation. Essentially, the ultrasound segmentation output is a real-time labelmap representation of the currently seen frame, and can then be used to apply the navigation learned on labelmaps to the real-time ultrasound images.
The use of a labelmap to learn a navigation policy for application in US scan is justified by previous works. Bartha et al [43] developed an open-source ultrasound image simulator called PLUS (Public Software Library for Ultrasound imaging research) to facilitate the training of US-guided spinal interventions. The simulator converts anatomical structures from segmented volumetric images into ultrasound images. Wang et al. [44] used this simulator to build a parallel control system, which means an artificial system that simulates the physical one. They show that it is possible to plan intra-operative ultrasound navigation of a probe for robotic transesophageal echocardiography (TEE) in a virtual environment. Ultrasound images are simulated by transforming a slice taken from a mesh model of the heart processed from an MRI volume, as can be seen in Fig. 11.
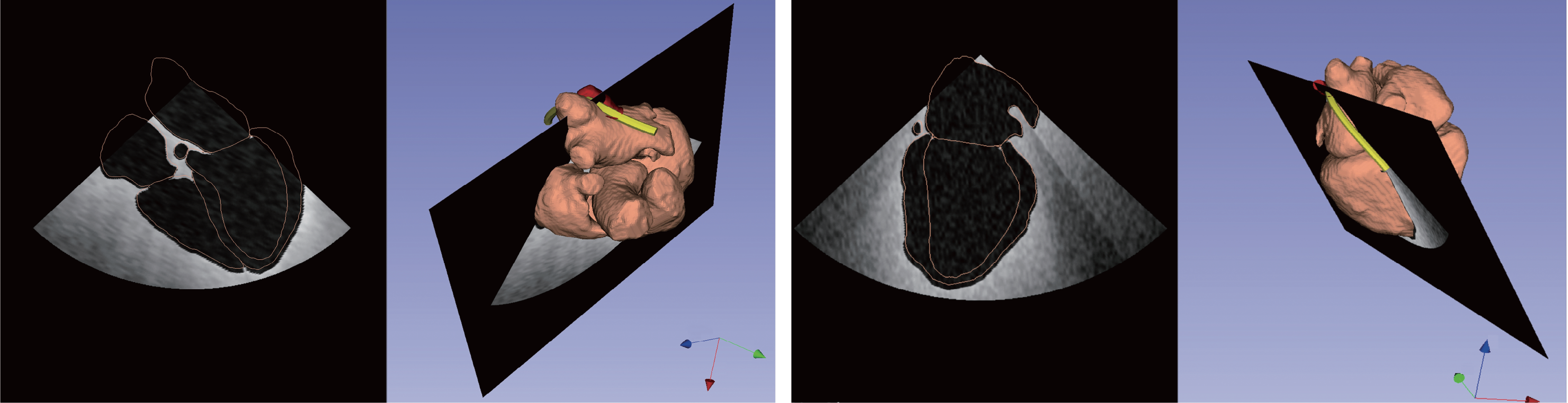
Fig. 11 PLUS simulator. The simulator converts anatomical structures from segmented volumetric images into ultrasound images. Figure from [43]#
To close the gap between simulated data and real ultrasound images, Li et al. [45] presented a Sim2Real framework to learn robotic US image analysis tasks based on simulated data for real-world deployment. This adopts a style transfer based on unsupervised contrastive learning to match the real US images with the simulation style. Thereafter, the task-specific model including a CNN for visual processing trained on simulated data can generalize predictions on real US images. The effectiveness of the method is demonstrated on an image regression task to predict the position of the probe based on the observed images in a TEE.
To justify the application of a navigation approach learned on labelmaps to real-time ultrasound images, it must be demonstrated that the same anatomical features used for training can be segmented during a live scan. To this end, Velikova et al. [46] proposed a Common Anatomical CT-US Space called CACTUSS. The method allows for real-time inference and segmentation of live ultrasound acquisitions, without the need for labeled ultrasound images for training. It takes advantage of the good resolution of CT images to segment tissues with ease. Each labeled tissue from the CT volume is then assigned six acoustic parameters that describe its physical characteristics and are passed to the simulator to create an intermediate representation (IR), a virtual modality with important characteristics from ultrasound while learning from annotated CT.
To learn the mapping between real ultrasound B-mode and IR, the method employs a Contrastive Learning for Unpaired image-to-image network (CUT) [47]. This enables the translation of ultrasound images in the domain of the IR. The generated IR has therefore a direct mapping to CT as well as to US images, working as a bridge between the two modes.
In a consecutive work [48], the authors improved the method by proposing an IR that is differentiable, and an end-to-end calibrated pipeline. The simulator learns to optimize the necessary physics-based parameters to render the virtual US image, guided by the downstream segmentation task. The system architecture is summarized in Fig. 12. The source code of this method is publicly available [2].
The simulator converts anatomical structures from segmented volumetric images into ultrasound images. US simulation images are rendered from a CT-labeled volume during training and are then segmented by a segmentation network. The differentiable image generator learns to optimize its parameters based on feedback from the segmentation task. Simultaneously, an unpaired and unsupervised image style transfer network is trained to learn the mapping from real US images to the IR.
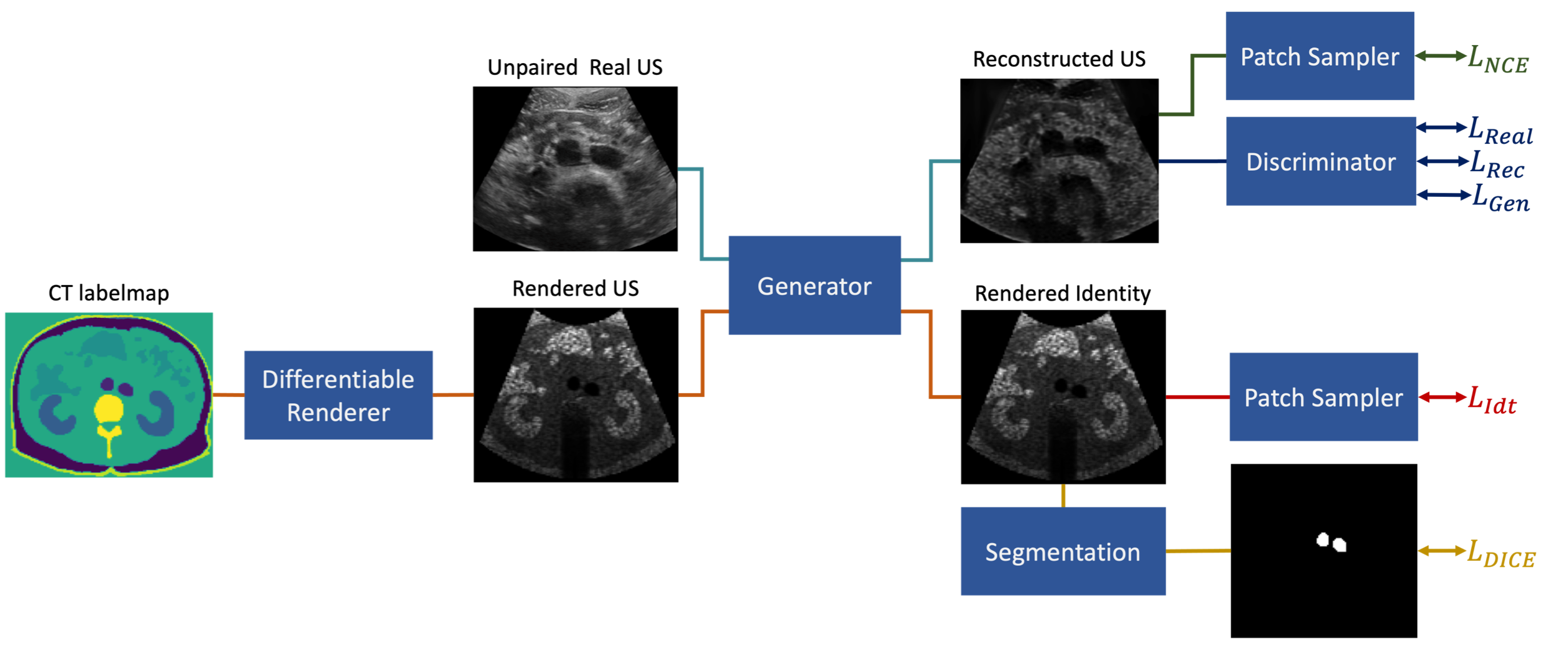
Fig. 12 The method proposed by [48] learns in parallel the representation of the IR from CT labeled volumes and US images. On one side, the downstream segmentation task updates the differentiable parameters of the US simulator. On the other, the CUT network learns the style transfer between US and IR images. Figure from [48] .#
Even though these methods have been presented to work together with CT images, the same approach can be used with MRI images, which have a similar resolution. In fact, all the simulation needs to work is a labelmap of the segmented tissues.
This thesis will not elaborate on bridging the gap between the labelmap volume space used for training and real-time US images. Given the research mentioned above, it will be assumed that the navigation policy can be applied with an appropriate intermediate representation to real-time US images, allowing the application of the autonomous navigation learned on labelmaps in real-time US scan.