Armscan Environment#
At the core of this project is the development of an environment that simulates the navigation of an agent in the image volumes, which is called Armscan Environment. The simulation environment defines the interaction between the agent and the labelmap volumes, simulating the process of navigating through the images to find the optimal slice. The environment is designed to provide the agent with the necessary information to make decisions and learn from its actions. This section describes the components of the simulation environment.
Gymnasium API#
The simulation environment has been built upon the API of the Gymnasium library [1] [3], which provides a unified interface for reinforcement learning tasks that has become a standard in the field. Gymnasium focuses only on the environmental aspects of the reinforcement learning problem, creating a clear separation between the agent and the learning algorithm. The only requirement it imposes on the agent is to produce a valid action at each step as specified by the environment’s action space. The environment processes the action and returns an observation and a reward, upon which the agent updates its policy. This design allows for a modular and flexible implementation, where the agent can be easily swapped out for different algorithms or models.
The advantage of using a standard API is that it makes the environment compatible with a wide range of reinforcement learning algorithms, allowing for easy integration with existing libraries and tools. Moreover, it helps project maintainability and scalability, as the environment can be easily extended or modified to accommodate new features or requirements.
Action Space#
The action space of the environment defines the possible actions that the agent can take at each step, and what kind of impact they have on the environment. The action space of the Armscan environment is designed to perform a range of actions that simulate the adjustments a radiologist might make when positioning a slice within a volume. These actions are defined by a combination of rotations and translations, constrained by the anatomical reference frame. Specifically, the manipulator can rotate the slice around the Z-axis to align with the wrist and around the X-axis to adjust angulation. Translations are applied along the X and Y axes to position the slice accurately, while movements along the Z-axis are avoided to maintain the integrity of the slice’s depth.
The action space is continuous, bounded by the volume size, and is modeled by the data class ManipulatorAction. It defines the rotation and translation attributes as tuples of two floats, which represent the angle in degrees and the distance in millimeters, respectively. Each action defines the parameters of the transformation matrix that will be applied to the volume to sample a new slice as described in Arbitrary volume slicing.
The action bounds define the minimum and maximum values for each action dimension. They can be set when instantiating the environment. The default values are set to \(\pm 180\) degrees for the rotations and to the maximum size of the current volume for the translations. The actions are normalized to the range \([-1, 1]\) by the bounds, so the agent’s output will be a vector with an action dimension equal to the number of degrees of freedom, with values in the range \([-1, 1]\). This is a common practice in reinforcement learning: it enhances stability by ensuring symmetry, aligns well with neural network activation functions, and improves gradient convergence during learning.
Actions can be converted from normalized arrays to ManipulatorActions class and vice versa using the from_normalized and to_normalized methods. At each step, the agent will output a normalized action, which will be converted to a ManipulatorAction object to be applied to the volume and sample the current slice. The actions are defined in the global coordinates of the volume, which means that any view of the volume is reachable at any time, independently of the current slice position. This allows the agent to explore the entire volume without any restrictions.
Dimensionality Reduction#
Dimensionality reduction in the environment is achieved through action space projections. It simplifies the agent’s task by reducing the number of controllable variables. Initially, the action space includes multiple degrees of freedom that the agent can adjust to position the slice. This high dimensionality can make the learning process more challenging, as the agent has to explore a large search space to find the optimal slice.
To address this, certain parameters are fixed at their optimal values, as pre-determined during the volume’s optimal slice labeling, as described in Optimal Slice Labeling. For instance, in some scenarios, only the Y-translation might remain adjustable, while X- and Z-rotations and X-translation are held constant. This approach was used to validate the environment with simplified experiments which will be further explored in the experiments section.
Observation Space#
The observation space of the environment defines the information that the agent receives at each step, which it uses to make decisions. It may consist of any data that is observable by the agent at every step, which must be organized into a format that the agent can process. Gymnasium provides structured interfaces to define the observation space through the Space class, which allows for a wide range of data types, including continuous, discrete, and multi-dimensional arrays.
The information available to the agent in the Armscan environment is not limited to the current slice but also includes the information about the cluster, the action, and most importantly the reward, which is an observable score of the current slice. Moreover, the past observations can be stacked to provide the agent with dynamic information, as common practice in many similar navigation tasks. Finally, an observable reward opens the possibility of keeping a memory of past actions that led to high reward states.
Different observation spaces are proposed to provide the agent with different levels of information. Moreover, wrappers can be used to modify the observation space, for example by stacking multiple observations or by adding additional information.
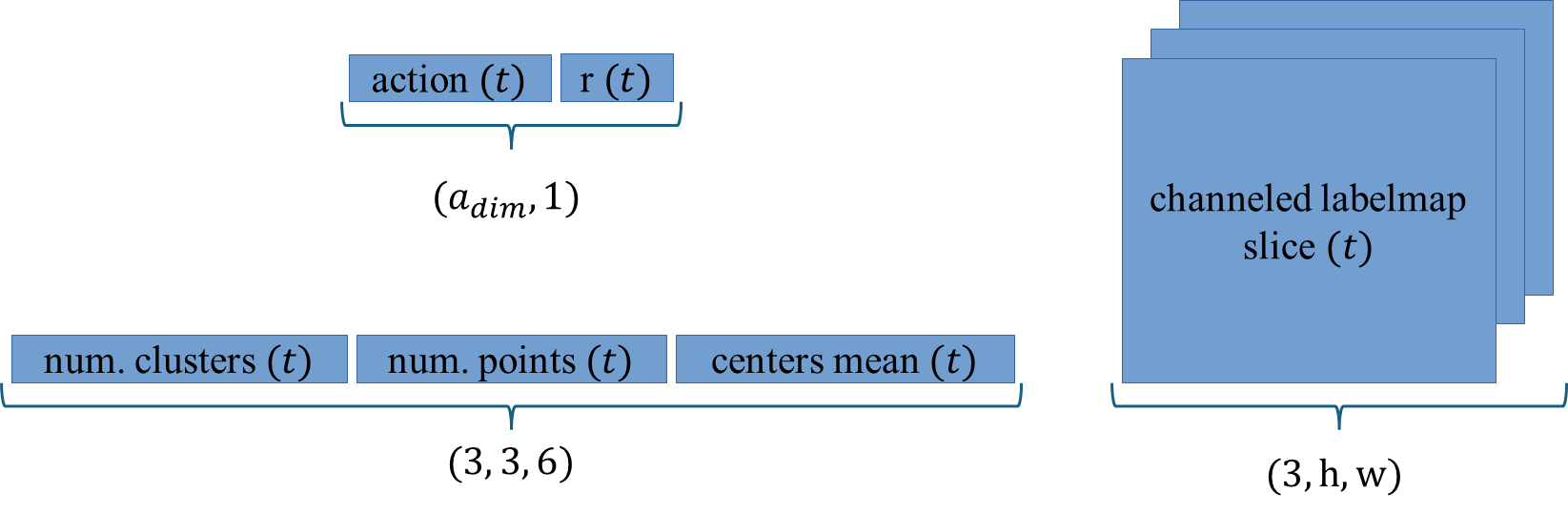
Fig. 24 Observation spaces of the Armscan Environment with annotated size. Top left: ActionRewardObservation. Bottom left: LabelmapClusterObservation. Right side: LabelmapSliceAsChannelObservation. Bottom right: LabelmapSliceAsChannelObservation.#
MultiBoxSpace Observations#
At the core of the observation space is the MultiBoxSpace class, a custom implementation that extends the Dict space of Gymnasium. Dict spaces are used to represent compound observation spaces, where each key-value pair in the dictionary corresponds to a different simple space. In the case of MultiBoxSpace, every key-value pair represents a different Box space, which is an n-dimensional continuous space defined by a low and high bound. This allows for a flexible definition of the observation space, where each key can represent a different component of the observation.
The decision to use MultiBoxSpace was motivated by the need to handle the specific shapes of different observation components. While Gymnasium’s Dict space provides a general structure for dictionary-based observations, it lacks native support for accessing and managing the shapes of the contained spaces. MultiBoxSpace addresses this limitation by providing a more specialized implementation that allows retrieval of the composite shape of the observation space as a list of tuples, each representing the shape of a different component. This structured approach is crucial for managing the high-dimensional data that the agent must process.
Action-Reward Observation#
The most simple observation of the environment is the ActionRewardObservation, which contains only the current action and reward. This observation is used to provide the agent with the most basic information about the environment, allowing it to learn the relationship between actions and rewards. The reward does already contain intrinsic information about the current slice. Also in the more elaborated observations, the information about the current action and latest reward is always present.
Labelmap’s Cluster Observation#
The LabelmapClusterObservation is a slightly more complex observation that contains some information about the current labels’ clusters. For each label (bones, tendons, and ulnar artery), it stores the number of clusters in the slice, the cumulative size of the clusters, and the mean between the centers of mass of the clusters in pixel coordinates. The idea is to provide the agent with some high-level information about the current slice, which can be used to guide the agent’s actions. For example, the agent might learn that slices with a low number of pixels in the bone cluster are not optimal, or that the relation between the the centers of mass of the clusters is important.
Labelmap’s Slice Observation#
The LabelmapSliceObservation is the most complex observation of the environment. It contains the whole image of the slice, which is a 2D array of pixel values representing the different labels. This observation provides the agent with the most low-level information about the current slice, allowing it to learn the relationship between the pixel values and the reward.
The LabelmapSliceAsChannelObservation is a variation of the LabelmapSliceObservation stores each label as a separate channel in the observation. This allows the agent to process the information in a more structured way, as each channel represents a different aspect of the slice.
However, these observations are also the most complex and computationally expensive, as they contain a large amount of high-dimensional data. To deal with the image dimension and the multimodality of adding the action and reward information, a custom network must be implemented.
These were the first observations implemented and tested in the environment, but unfortunately, they did not provide the expected results. The agent was not able to learn the task and the training was not converging. This was due to the high dimensionality of the observations, which made the learning process very slow and unstable. For this reason, the environment was simplified by reducing the dimensionality of the observations, as described in the previous sections.
Observation Wrappers#
Observation wrappers play a crucial role in enhancing the observation space by enabling the modification and augmentation of observations on the fly. Wrappers are used to preprocess the observations before they are passed to the agent, allowing for the addition of new information or the transformation of existing data. Wrappers make the environment more modular and flexible, and they can be easily chained to modify the observation space.
Stacked Observations#
The PatchedFrameStackObservation, which is almost a copy of the FrameStack wrapper of Gymnasium, is a wrapper that stacks the observations of the last \(n\) steps together. This wrapper is used to add temporal information to the agent’s observations, allowing it to learn from the history of its actions. It was necessary to create a copy of the original wrapper in order to deal with some compatibility issues with the MultiBoxSpace observation.
Best Action Memory#
To keep the memory of the actions that led to the highest reward states in an episode, the BestActionRewardMemory wrapper was implemented. This wrapper concatenates to the current observation the best \(n\) actions and reward pairs encountered so far in the episode. At every step, the wrapper checks if the current reward is higher than the best rewards in the memory. If so, the memory is updated with the current action-reward pair, and the smallest reward is removed. This information can be used by the agent to learn from past experiences and to guide its actions toward high reward states.
Deep Reinforcement Learning Agent#
As mentioned above, the architecture of an RL solution is modular, and the environment is well separated from the agent. This allows the easy integration of different agents, which can be swapped out to test different algorithms or models. The choice of the agent must consider the action space, which is continuous. This necessitates the use of an algorithm that can handle continuous action spaces, such as Soft Actor-Critic (SAC), which is a state-of-the-art algorithm for continuous control tasks and has shown promising results outperforming Proximal Policy Optimization (PPO) in the Armscan Environment.
Tianshou#
In this project, the agent is implemented using the Tianshou library [2] [4] , which provides a wide range of deep-reinforcement learning algorithms and tools. Tianshou offers high flexibility and modularity, allowing for easy customization and extension of the agent’s architecture.
Tianshou’s backend is built upon PyTorch, for the implementation of the neural networks, and Gymnasium, for the environment interface. It supports vectorized environments, which can be used to parallelize the agent’s training process, and provides a set of utilities for logging and monitoring the agent’s performance. Moreover, Tianshou supports any user-defined PyTorch networks, given that the inputs and outputs are compatible with the agent’s API.
Tianshou offers a high-level interface to quickly set up an experiment and train an agent with the state of the art algorithms. The ExperimentBuilder class provides a simple way to define the setup of the experiment using default configurations, that can be adjusted to the user’s needs.
Customized Multimodal Network#
The complexity of the LabelmapSliceAsChannelObservation necessitated the design and implementation of a specialized neural network architecture capable of effectively processing the multimodal inputs received from the environment. The customized network MultiMod_ArmScan_Net, is a composite architecture that combines convolutional neural networks (CNNs) for processing image-based observations with multilayer perceptrons (MLPs) for handling action and reward inputs. The goal of this design is to enable the agent to learn from both the visual data of the environment and the sequential information of past actions and rewards, thereby improving decision-making in complex navigation tasks.
The CNN component is designed to process the channeled slice observations, which represent the visual data from the environment, very similarly to the DQN architecture, proposed in [5] . This network component consists of three convolutional layers, each followed by a ReLU activation function. These layers progressively extract and refine features from the input data, culminating in a flattened output that serves as an abstract representation of the visual observations.
In parallel, the MLP component processes the sequential information of the agent’s actions and the corresponding rewards. This MLP is structured with two linear layers, both activated by ReLU functions. The input to the MLP is a concatenation of the last action taken by the agent and the previous reward received.
The outputs from the CNN and MLP are then concatenated and passed through an additional MLP, which serves as the final processing stage of the network. This final MLP is composed of three linear layers, each activated by ReLU functions. This final stage integrates the multimodal information from both the visual and sequential data, producing the actions’ Q-values.
To facilitate the integration of this network into the reinforcement learning pipeline, a custom actor factory, referred to as ActorFactoryArmscanNet, was developed. This factory method ensures that the MultiMod_ArmScan_Net is appropriately constructed and deployed within the broader experimental framework. The factory handles the specifics of the observation and action shapes derived from the environment, ensuring that the network is correctly configured for the given task.
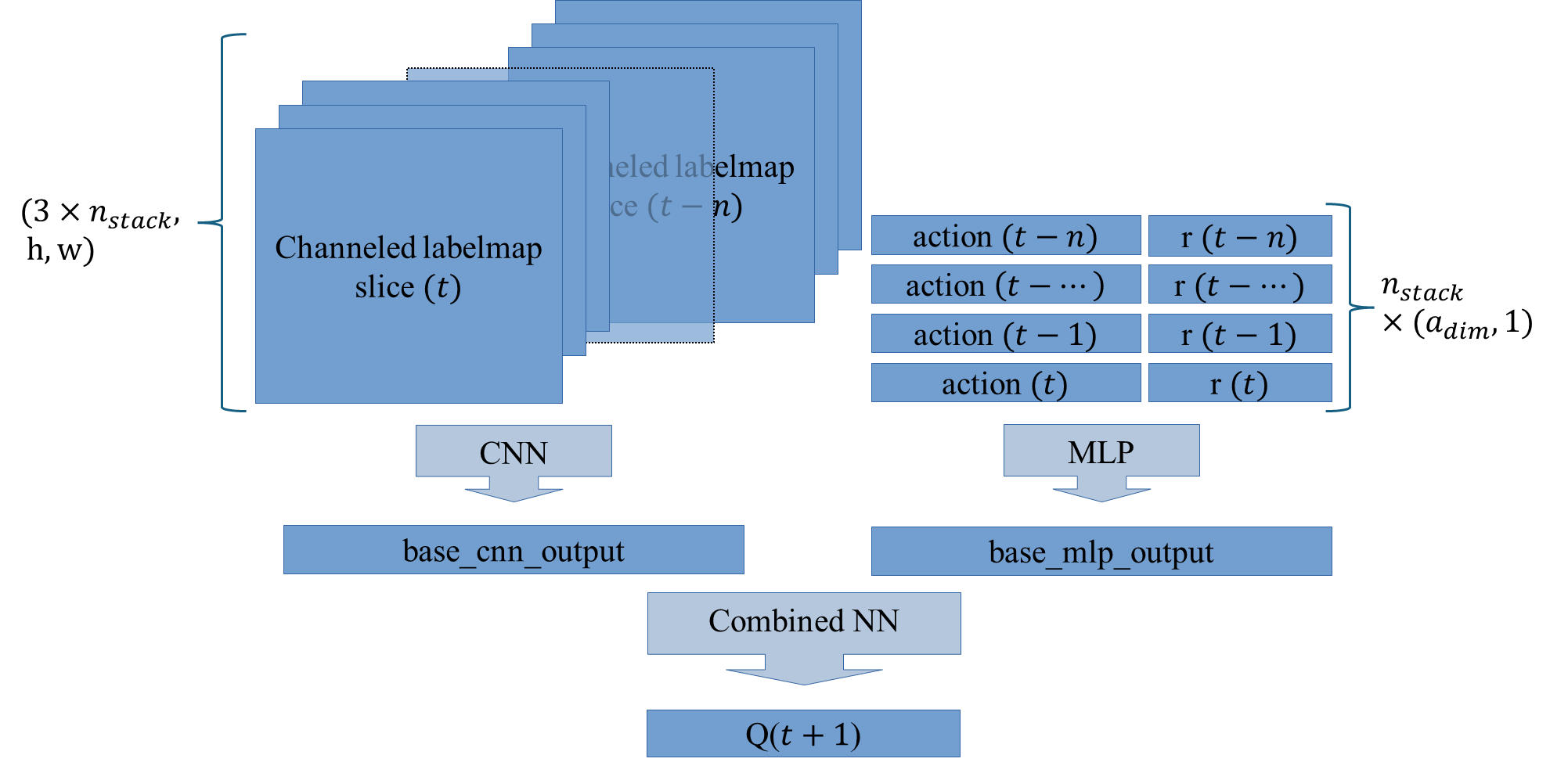
Fig. 25 Customized multimodal network architecture for the Armscan Environment computing Q-values from a stack of \(n\) LabelmapSliceAsChannelObservation.#
Proximal Policy Optimization (PPO)#
Proximal Policy Optimization (PPO), see Proximal Policy Optimization, is a widely used algorithm in reinforcement learning due to its simplicity and effectiveness in various environments. PPO works by optimizing a clipped surrogate objective function, which prevents large updates to the policy, ensuring stability during training. Despite its success in many applications, PPO showed significant challenges when applied to the Armscan Environment.
During training, the PPO agent consistently failed to converge. Instead of learning a stable policy, the agent’s performance often diverges. This instability was likely due to the high dimensionality and complexity of the observation space combined with the intricacies of navigating 3D medical volumes. The exploration strategies in PPO did probably not sufficiently cover the vast action space, leading to poor exploration and suboptimal policy updates. Given these difficulties, a pivot was made to another algorithm better suited for continuous action spaces.
Soft Actor-Critic (SAC)#
Soft Actor-Critic (SAC), see Soft Actor-Critic Algorithm, is a more recent algorithm specifically designed for continuous action spaces. SAC optimizes a stochastic policy by maximizing both the expected reward and the entropy of the policy, which encourages exploration by preventing premature convergence to a deterministic policy.
The entropy term in SAC ensured a good exploration of the action space. This was particularly important in navigating the complex 3D volumes, allowing the agent to explore a wide range of possible actions and discover effective strategies. SAC’s use of multiple critics (two Q-networks) provided stability during training. By employing double Q-learning, SAC mitigated the overestimation bias, leading to more reliable value estimates and smoother learning curves. SAC showed significant promise in the Armscan Environment. The agent was able to learn a stable policy that effectively navigated the medical volumes to identify optimal slices. The combination of entropy-driven exploration and stable critic networks proved to be well-suited for this task.
All Together: Episode Loop#
The episode loop is the core of the reinforcement learning process, defining the interactions between the agent and the environment. The loop starts by resetting the environment and initializing the agent’s state. At each step, the agent receives an observation from the environment, processes it through its policy network, and outputs an action. The action is then passed to the environment, which applies it to the volume and returns the next observation and reward. This process is repeated until the episode ends, at which point the agent updates its policy based on the collected experiences.
At every reset, the environment samples a new volume for the agent to navigate and applies a random transformation to add variability. The agent receives the initial observation and reward, and the episode loop begins. The agent’s policy network processes the observation and outputs an action, which is applied to the volume to sample a new slice. The environment returns the new observation and reward, and the process repeats until the episode terminates.
The termination criteria of the Armscan environment is fulfilled when the agent reaches a slice with a reward higher than a preset threshold \(\delta\), which in the experiments was set to \(\delta=0.05\). However, the episode can also be truncated if the agent reaches a maximum number of steps. This ensures that the agent does not get stuck in an infinite loop and that the training process remains stable.